Strukturovaná data jsou způsob, jak vyhledávačům předat informace o obsahu našich stránek.
Drtivá většina webů je však nemá implementovány správně. Vyhledávače tak musí mnohem více “přemýšlet” nad tím, co na stránkách vlastně je.
Zjistěte, co dělá většina lidí špatně a jak se tomu vyhnout a na konci článku si ode mne ukradněte vzorové kódy k použití.
Obsah článku
Opáčko na začátek: Co jsou strukturovaná data a k čemu slouží
Strukturovaná data jsou způsob předávání informací robotům unifikovaným a strukturovaným způsobem.
Vyhledávače je používají k získání podkladů pro zobrazení speciálních funkcí ve výsledcích vyhledávání (například hvězdičky hodnocení produktů).
Abych to řekl zjednodušeně: strukturovaná data jsou způsob, jak strojům přeložit obsah stránky způsobem, který naprosto jednoznačně chápou.
Existuje několik typů strukturovaných dat:
- microdata
- RDFa
- JSON-LD
Nejčastěji se setkáte se strukturovanými daty ve formátu JSON-LD psaných podle univerzálně používaného Schema.org protože jsou nejjednodušší na implementaci.
Strukturovaná data NEJSOU rich snippets
Rich snippets jsou speciální funkce, které Google zobrazuje u výsledků vyhledávání (například hvězdičky, cena a skladovost produktu atd.).
A ačkoliv informace Google čerpá ze správně implementovaných strukturovaných dat, nejedná se o totéž. Strukturovaná data jsou způsob zápisu informací, zatímco rich snippets obohacené výsledky vyhledávání.
Toto rozdělení je důležité chápat především proto, že strukturovaná data umí dělat mnohem více, než jen zajistit hvězdičky u vaší stránky ve výsledcích vyhledávání Google.
Pomocí strukturovaných dat můžete předat mnohem více informací, které vyhledávače mohou použít pro pochopení obsahu stránky a její zobrazování na správná slovní spojení.
Většina implementací vytváří chaos místo pořádku
Většina strukturovaných dat, které jsem kdy měl možnost vidět, odpovídala pouze té nejmenší možné implementaci, kterou vyhledávače doporučují.
Často jako copy-paste z volně dostupných generátorů strukturovaných dat, kterých na internetu najdete požehnaně.
Problém je v tom, že na stránkách se pak často nachází několik samostatně popsaných entit, které mezi sebou nemají žádný vztah.
Vyhledávač tak na první dobrou nepozná, o které z nich daná stránka vlastně je. Je předmětem stránky produkt? Článek? Informace o autorovi textu? Je naším úkolem tuto informaci komunikovat jednoznačně.
Entity jako základ pro sémantické SEO
Entita je definována jako jednoznačně identifikovatelný a konkrétní objekt nebo koncept, který má vlastní existenci a je rozpoznatelný bez ohledu na jazyk či kontext.
Jednoduše řečeno je to něco, co jednoznačně existuje a má jasný a pochopitelný význam.
Pokud budete vyhledávat “produkty Apple”, tak ve výsledcích vyhledávání rozhodně nenajdete informace o odrůdách jablek a to ani v případě, že se na daných stránkách o jablkách budou nacházet slova “produkt” a “apple”.
Díky “pochopení” toho, že jablko a společnost jsou rozdílné entity s rozdílnými vlastnostmi, dokážou vyhledávače mnohem lépe chápat kontext.
Správná implementace strukturovaných dat v tomto pochopení vyhledávačům pomáhá.
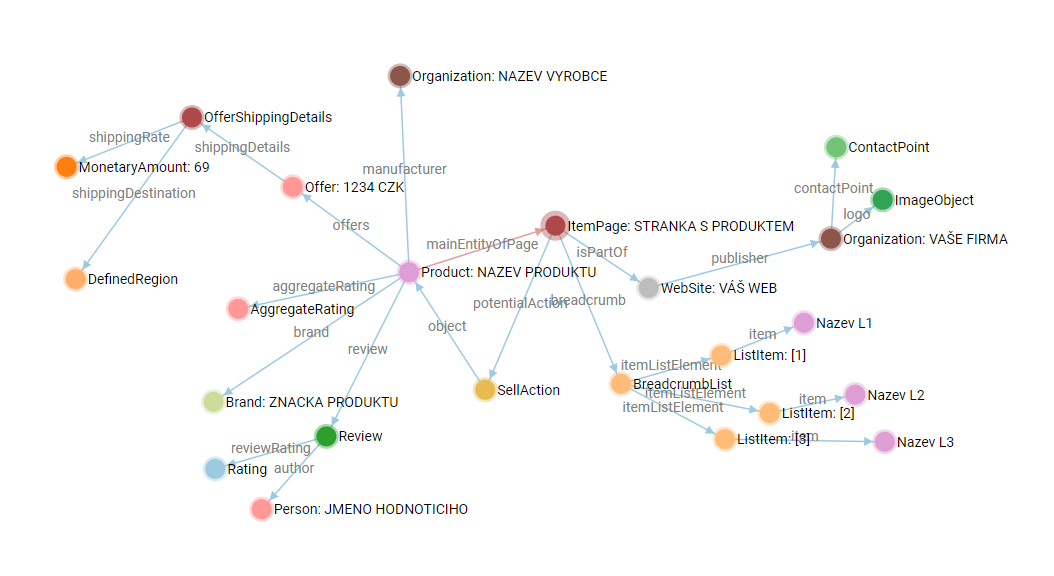
Ukázka běžné, ale nedokonalé implementace: Nepropojené entity
I přesto, že ukázka na obrázku níže neobsahuje žádné chyby a vypadá naprosto v pořádku, nejedná se o správnou implementaci.
Jak si můžete všimnout, tak i samotný validátor ukazuje celkem 5 SAMOSTATNÝCH entit, které se na stránce nachází.
Vyhledávač tyto informace přečte a musí si sám určit, která z těchto entit je hlavní, jaký je mezi entitami vztah a o čem daná stránka vlastně je.
To my nechceme. My chceme, aby to bylo naprosto jasné již z našeho kódu a abychom se nemuseli spoléhat na interpretaci ze strany vyhledávače.
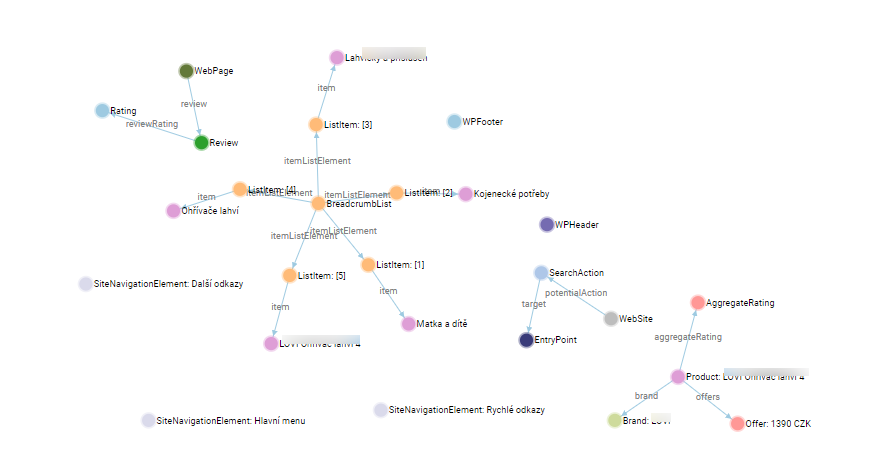
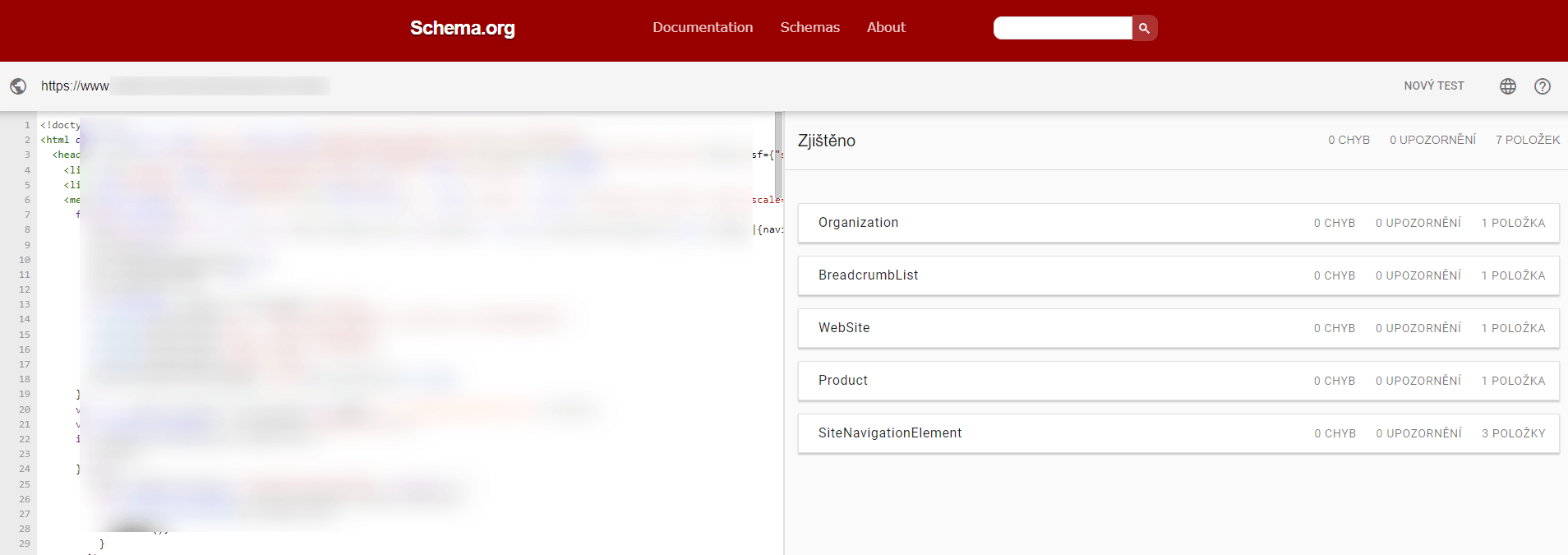
Správná implementace a propojené entity
Při ideální implementaci by to mělo vypadat tak, že strukturovaná data, stejně jako stránka sama, popisují pouze jednu hlavní entitu.
Všechno ostatní je pouze doplnění informací, které se k této hlavní entitě vážou.
Tato ukázka z validátoru (validator.schema.org) ukazuje, že nástroj na kontrolu strukturovaných dat na stránce našel pouze jednu hlavní entitu “itemPage”.
I přesto tato stránka obsahuje stejný objem informací a entit jako na předchozích screenech.
Zásadní rozdíl, je ten, že entity už nejsou uvedeny samostatně, ale jsou “schovány pod” vybranou hlavní entitu a vytváří tak jednotný a strojově pochopitelný knowledge graph (vizualizaci můžete udělat v https://classyschema.org/visualisation).
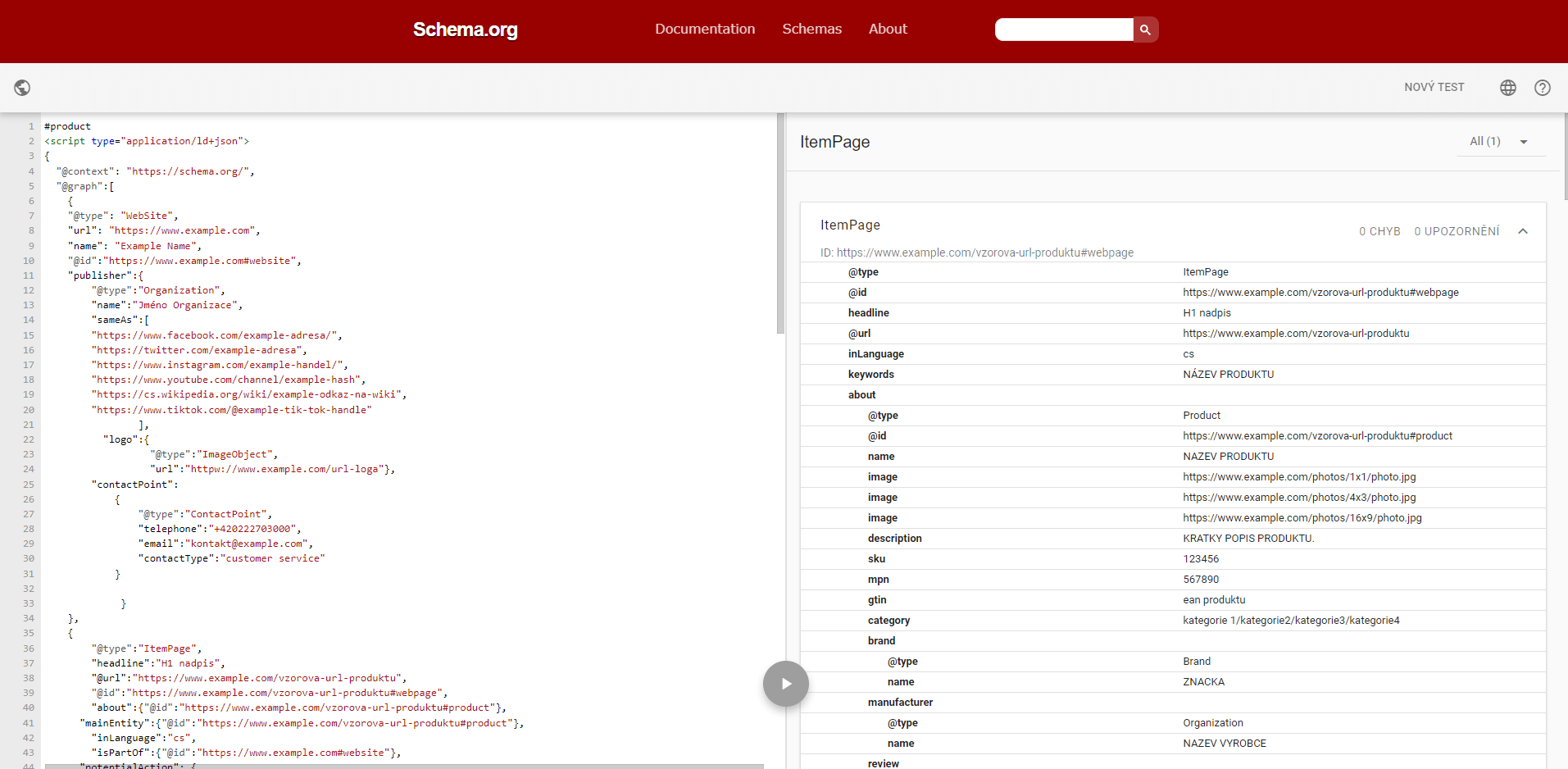
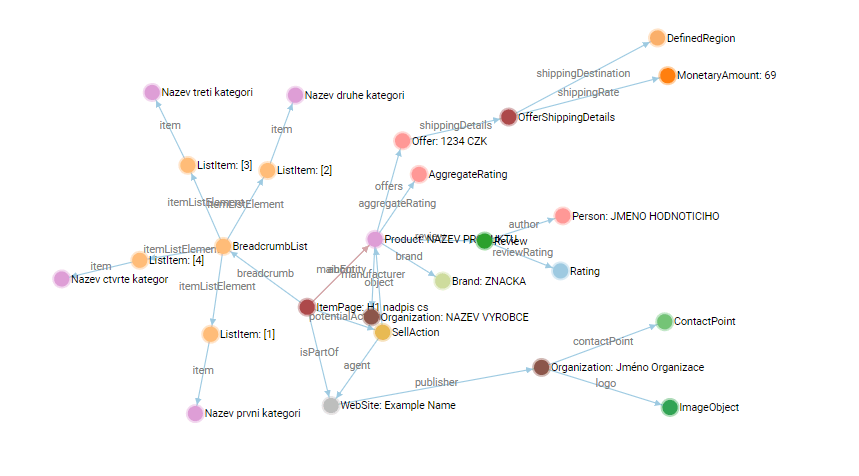
Hlavní entita určí, o čem je stránka
Abyste dali vyhledávačům jasně najevo o čem daná stránka je, musíte určit hlavní entitu.
To můžete udělat pomocí dvou různých (k sobě inverzních) properties.
- mainEntity, nebo
- mainEntityOfPage
mainEntity funguje tak, že začnete pomocí strukturovaných dat popisovat stránku (WebPage) a jako součást uvedených informací vložíte mainEntity a tu popíšete.
V podstatě tak vyhledávačům řeknete: tady je nějaká stránka XY a ta se věnuje této hlavní věci.
mainEntityOfPage funguje přesně naopak. Pomocí strukturovaných dat začnete popisovat hlavní předmět stránky (například produkt) a k tomu uvedete, že se jedná o hlavní entitu stránky XY.
Jinými slovy tak vyhledávačům řeknete: tady je nějaká věc a ta je tím hlavním o čem pojednává tato stránka.
Jak entity propojit: dva základní způsoby
Propojit entity v kódu lze dvěma způsoby – vnořením a pomocí ID.
Vnořování funguje tak, že v jedné části kódu je vložena další, která s ní souvisí. Například při popisování článku do něj v kódu vložím autora. Nebo při popisování organizace do ní vložím pobočku.
Někdy je ale uvedených informací už tolik (nebo je potřeba je v různých částech kódu opakovat), že vám vnořování může poměrně zkomplikovat život. Pro takové situace existuje druhé, často opomíjené, řešení.
Propojení pomocí ID funguje tak, že každé entitě přidáte vlastní unikátní identifikátor (většinou stačí URL, nebo URL + fragment) a na ten se v dalších částech kódu odkážete.
Vztahy mezi entitami se učit nemusíte
Protože entit je nepřeberné množství a hledání způsobů jak je mezi sebou propojit by vám sebralo nehezky dlouhý kus života, doporučuji využít nástroj SchemaPaths od Schema App.
Stačí zadat dvě entity, které chcete propojit a nástroj vám pak zadarmo ukáže, jaké mezi nimi mohou být vztahy.
Vzorové kódy ke zkopírování
Abyste měli svou práci co nejsnazší, připravil jsem vám vzorové kódy pro 4 základní typy stránek. Ty si můžete libovolně zkopírovat a doplnit. A pokud si nebudete vědět rady, zeptejte se ChatGPT (nebo jiné AI, která vám s tím snadno a rychle pomůže)